8月26日、 毎月勤労統計調査の改善に関するワーキンググループ の 第2回会議 があった。 オンラインで傍聴できる とのことだったので、申し込んで傍聴してみた。
この第2回会議の主たる議題は、毎月勤労統計調査の「ベンチマーク更新」について。2016年の経済センサス-活動調査の情報または事業所母集団データベース2019年次フレームの情報を利用して2022年1月にベンチマーク更新をおこなう、という方針に基づいて作成した試算の検討がおこなわれた。この方針は 第1回会議 (2021-07-09) において提案されていたが、これらのふたつの情報源のどちらも精確さを欠くため、試算を作成しての対応を検討することになったものである (第1回会議の 議事録 を参照)。
第2回会議に提出されたこの試算結果をみると、500-999人規模事業所の労働者数が2割近く減ったり、「きまって支給する給与」平均が1000円超増える (いずれも事業所母集団データベース2019年次フレームに基づく試算) など、大きな変動が生じることが予測されている。この試算結果は、現状の毎月勤労統計調査データがセンサスによる母集団情報から大きくはずれている (だからそれを修正するとギャップが生じる) ことを意味する。本来であれば、そのようなずれが生まれる原因を究明し、毎月勤労統計調査の調査・集計方法を見直すことが必要になる局面だ。しかし、この会議では、そうした疑義はまったく提示されず、もっぱらベンチマーク更新の基準となる情報として何が適切かに限定した議論に終始した。
この記事では、現在入手可能な情報を使い、毎月勤労統計調査のベンチマーク更新で生じるギャップがどのような原因によるものかの推測をおこなう。
目次
- ワーキンググループ会議内容
- 問題の所在
- 「ベンチマーク」の3つの意味
- データ
- 毎勤原表
- 情報の抽出とテキスト・データ作成
- 分析のためのRスクリプト
- 月々の労働者数推計とベンチマーク更新の原理
- 2004年以後の毎月勤労統計調査とセンサスの乖離
- センサスによる労働者数の推定
- 5-29人規模事業所
- 30-99人規模事業所
- 100-499人規模事業所
- 500-999人規模事業所
- 1000人以上規模事業所
- 月々の労働者数推計の有無による差の評価
- 議論
- 付録:使用したプログラムとデータ
ワーキンググループ会議内容
「毎月勤労統計調査の改善に関するワーキンググループ」は、厚生労働省の「厚生労働統計の整備に関する検討会」の下に2021年6月23日に設置された。メンバーはつぎのとおり:
- 加藤久和: 明治大学教授 (主査)
- 稲葉由之: 青山学院大学教授
- 風神佐知子: 慶應義塾大学准教授
- 高橋陽子: 労働政策研究・研修機構副主任研究員
- 樋田勉: 獨協大学教授
第2回会議には、メンバーのほかに西郷浩 (早稲田大学教授) が参加していた (ほかにもメンバー外の参加者があったかもしれないが、確認できていない)。
議題は「毎月勤労統計調査におけるベンチマークの更新等について」。最新の経済センサス-活動調査 (2016年6月) または事業所母集団データベース2019年次フレームの情報を利用してベンチマーク更新をおこなう方法の提案と、会議時点での最新のデータ (2021年5月分の毎月勤労統計調査) に適用した場合の試算結果が報告された。(資料1「ベンチマーク更新の方法等について」https://www.mhlw.go.jp/content/10700000/000823050.pdf)
2016年経済センサス-活動調査は民営事業所だけの調査であるため、公営の事業所の労働者数の値を補う必要がある。資料では、2014年の経済センサス-基礎調査の公営事業所労働者数をそのまま加算する方法をはじめ、5種類の補正案が提示された。
「事業所母集団データベース」は、全国の全事業所を登録するデータベースとしてつくられているもの。2019年経済センサス-基礎調査などの情報をもとに、2019年6月1日時点のデータを整備したのが「2019年次フレーム」である。このデータベースでは、事業所を把握することに重点が置かれているため、そこに雇用されている労働者の数については古いまま更新されていないことが多く、そのために、労働者数のデータとしては不正確な面がある。今回の会議資料では、この点について補正をおこなわないままでの試算結果が示されている。
事業所母集団データベース2019年次フレームに基づくベンチマーク更新をおこなった場合、「きまって支払われる給与」の平均額が、26万2404円から26万3788円へと1,384円 (0.5%) 上がる試算結果となっている (資料1 の10ページ)。この変動は、事業所母集団データベース2019年次フレームの事業所規模別・産業別の労働者数が、毎月勤労統計調査の当時の推計母集団労働者数から乖離していたことを示している。この乖離分(=ギャップ)を2021年5月のデータにおいて埋め合わせたらどうなるかを試算した結果、このようになったわけである。
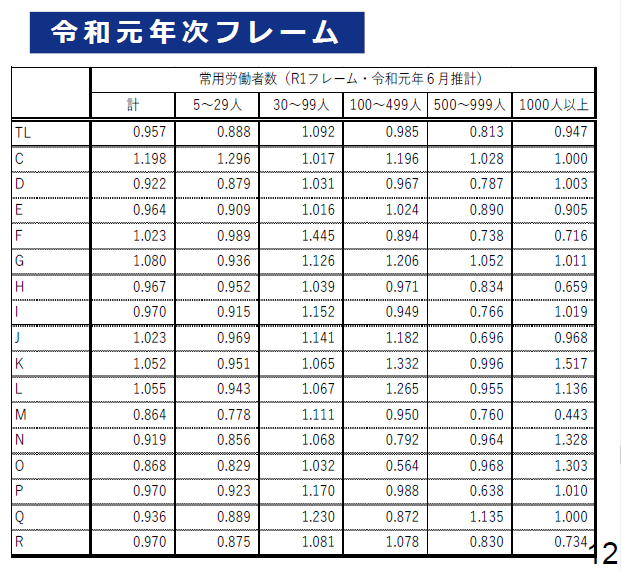
試算結果から、「2019年6月」時点での「ギャップ率」を事業所規模と産業による層別に示した表がつぎのものである。5-29人規模事業所のギャップ率が0.888となっているのは、事業所母集団データベースの労働者数 (a) よりも毎月勤労統計調査で当時推計していた母集団労働者数 (b) のほうが多く、a/b = 0.888 であったことを意味する。5-29人規模事業所は、ほとんどの産業でギャップ率が1未満となっており、a < b であったことがわかる。特に産業分類M (宿泊業、飲食サービス業) においてはギャップ率0.778とかなり小さい。他方、500-999人の比較的大きな事業所でも、ギャップ率が0.813と小さい値であり、やはり毎月勤労統計調査の母集団労働者数の推計が過大になっている。
https://www.mhlw.go.jp/content/10700000/000823050.pdf
―――――
厚生労働省 政策統括官 (統計・情報政策担当) (2021-08-26)「ベンチマーク更新の方法等について」(第2回 毎月勤労統計調査の改善に関するワーキンググループ https://www.mhlw.go.jp/stf/newpage_20075.html 資料1) p. 12
「TL」は全産業。C-Rの各産業分類については同資料 p. 11 など参照。
2016年経済センサス-活動調査の場合、公営事業所の労働者数の補正方法が5種類提案されているため、それにしたがってギャップ率の表も5つ掲載されている (ただしそれらの間で、数値は大きくはちがわない)。つぎに載せたのはいちばん最後の案5であるが、事業所母集団データベースによるギャップ率と同様、5-29人規模事業所と500-999人規模事業所においてギャップ率が大きい傾向がある。
https://www.mhlw.go.jp/content/10700000/000823050.pdf
―――――
厚生労働省 政策統括官 (統計・情報政策担当) (2021-08-26)「ベンチマーク更新の方法等について」(第2回 毎月勤労統計調査の改善に関するワーキンググループ https://www.mhlw.go.jp/stf/newpage_20075.html 資料1) p. 12
「TL」は全産業。C-Rの各産業分類については同資料 p. 11 など参照。

ただし、2016年経済センサス-活動調査に基づいてベンチマーク更新をおこなった場合の試算結果 (資料1 の10, 13ページ) では、労働者数の変動の比率はそれほど大きくなく、きまって支給する給与の平均値にもほとんど変動がない。これらは、現行の毎月勤労統計調査は2014年経済センサス-基礎調査に基づくベンチマーク更新を2018年1月にすませていること (そのため2016年経済センサス-活動調査に基づくベンチマーク更新による変化は2014-2016年の2年間の変化だけを反映する) や、産業分類M (宿泊業、飲食サービス業:賃金が低い傾向がある) のギャップ率がそれほど低くないといったことによるのだろう。
会議資料には、このほか、ベンチマーク更新のために生じる過去の数値との断層を補正して「指数」をなだらかにつなぐ方法についても説明がある。これらの資料が提示されたうえで、どの方法を採用してベンチマーク更新をおこなうのがよいかについて委員からの意見があったが、結論をみたわけではない。最終的にどのような方法をとって統計を整備していくかについては、次回以降の会議での決定になるのだと思う。
問題の所在
ベンチマーク更新でギャップが生じるのは、要するに、つぎのふたつの値がちがうという問題である。
- 毎月勤労統計調査が推計する母集団労働者数
- 経済センサスや事業所母集団データベース (以下では単に「センサス」という) が記録する労働者数
これらの間に存在する食い違いについて、前者を修正して後者にあわせるのが「ベンチマーク更新」である。ベンチマークを更新すると、層別に推計される母集団労働者数が突然増えたり減ったりするので、層の構成比が変わる。そして、この推計母集団労働者数をウエイトとして計算される平均賃金などの集計値も、突然上がったり下がったりすることになる。
このようなベンチマーク更新の方法がずっととられてきた背後には、つぎのふたつの前提がある:
- 毎月勤労統計調査が推計する母集団労働者数とセンサスが測定する労働者数は、おなじものを指している
- センサスの労働者数のほうが、真の値に近い
まず、これらの前提は正しいのか? ということが問題である。この問題については、稿をあらためて論じることにしよう。
しかし、もしもこれらの前提を承認することにしたとしても、では現行のベンチマーク更新のやりかたが適切であるのかどうかは、また別の問題である。労働者数に食い違いがあらわれる典型的なケースとして、つぎの2種類を考えてみよう。
- センサスの労働者数は増減しているのに、それが毎月勤労統計調査の労働者数推計に反映していない
- センサスの労働者数は一定なのに、毎月勤労統計調査の労働者数推計が増減している
前者に対しては、母集団労働者数の変化を忠実に反映するよう、月々の労働者数推計の方法を改善するのが本来のありかたである。それでも生じてしまう微細なちがいがある場合に、それを修正する方法として、センサスの情報を使った労働者数の是正をおこなうことになるだろう。
後者の場合には、母集団の労働者数が一定なのだから、毎月の労働者数も一定でかまわないのであり、変化させる理由がない。月々の労働者数推計で労働者数を変化させることがかえって統計の精度を下げているのだから、まずこれを停止すべきである。
「ベンチマーク」の3つの意味
毎月勤労統計調査における労働者数推計の実態がどうであったかを検討する前に、「ベンチマーク」なる用語の意味するところを確認しておこう。
このワーキンググループの第1回 (7月9日) の資料3によれば、「ベンチマーク」はつぎのように説明されている:
「経済センサス-基礎調査」等の結果を労働者数のベンチマーク(水準点)として、毎月勤労統計調査の集計に用いる母集団労働者数の実績との乖離を是正するために、母集団労働者数を更新する作業を行っている。この作業を「ベンチマーク更新」という。
https://www.mhlw.go.jp/content/10700000/000802076.pdf
―――――
厚生労働省 (2021-07-09)「毎月勤労統計調査におけるベンチマーク更新等」(第1回 毎月勤労統計調査の改善に関するワーキンググループ https://www.mhlw.go.jp/stf/newpage_19486.html 資料3) p.1
毎月勤労統計調査の集計に用いる母集団労働者数を、センサスの結果を水準点として修正した場合の、その水準点となるセンサスの結果のことを、「ベンチマーク」という。この第1回会議の議事録 https://www.mhlw.go.jp/stf/newpage_20584.html によると、事務局からの説明 (野口統計管理官) でつぎのような表現がたくさんでてくる。
- 「事業所の全数調査である経済センサス等の結果を、ベンチマーク若しくは一般的に言うと真の値として取り扱い」
- 「従来は経済センサス、事業所・企業統計調査などをベンチマークとして活用しています」
- 「前回、平成30年1月分調査から平成26年の経済センサス‐基礎調査をベンチマークとして、ベンチマーク更新をしています」
- 「仮に今回、事業所母集団データベースを毎月勤労統計調査のベンチマークとして定めることとした場合」
- 「乖離を是正するために全数調査である経済センサス等の結果を用いてベンチマーク、いわゆる水準点として母集団労働者数を設定する方法を取っているところです」
- 「令和3年の経済センサス‐活動調査では全数を調査し、労働者数も把握されているので、これをベンチマークとしないという選択肢はないかと考えています」
ここで「ベンチマーク」と呼ばれているのは、経済センサスや事業所母集団データベースなど (あるいはそれらの結果として算出された数値) のことである。毎月勤労統計調査の報告書 (年報) をまとめて市販する『毎月勤労統計要覧』では、最新の2020年版 (令和2年版) になって、この定義を採用している。
平成30年1月のギャップ修正においては、ベンチマークを「平成21年経済センサス-基礎調査」(平成21年7月1日現在) から「平成26年経済センサス-基礎調査」(平成26年7月1日) に変更したことから、平成21年7月分以降について行った。
―――――
厚生労働省政策統括官 (統計・情報政策担当) (2021)『毎月勤労統計要覧』(令和2年版) 労働法令協会 ISBN:9784845214334 p. 297
この場合、「平成21年経済センサス-基礎調査」とか「平成26年経済センサス-基礎調査」とかが「ベンチマーク」にあたる。[2021-09-22追記:ただしこの直前の p. 296 には、後述の第2の定義に相当する記述もある]
ところが、それまでの毎月勤労統計調査関連の資料では、ちがう意味で「ベンチマーク」ということばを使っていた。
最新の事業所統計調査結果が判明したときには、それから作成した値(事業所統計によるベンチマークという)を前月末母集団労働者数とする。
―――――
労働大臣官房政策調査部 (1990) 『毎月勤労統計要覧』(平成2年版) 労働法令協会 ISBN:4897644550 p. 195
この定義では、センサス (ここでは事業所統計) そのものの結果ではなく、そこから作成した前月末母集団労働者数のことを「ベンチマーク」と呼ぶ。『毎月勤労統計要覧』に登場する「ベンチマーク」は、2015年版 (平成27年版) まではこの意味だった。[2021-09-22追記:2020年版 (令和2年版) p. 296 には「常用労働者のベンチマークの数値 (センサスから作成した前月末母集団労働者数)」との記述があり、これはこの第2の定義に相当する。]厚生労働省による現在の解説ページ https://www.mhlw.go.jp/toukei/list/30-1c.html#01 にも、おなじ定義が載っている。
さらに、『毎月勤労統計要覧』の2016年版 (平成28年版) から2019年版 (令和1年版) までは、またちがう定義を採用している。
単位集計区分毎に前月のベンチマーク (注1) に対して、標本事業所における前月から当月への変動を反映し、当月の値を算出するリンク・リラティブ方式で常用労働者を推計している。
〔……〕
(注1) 前月の母集団労働者数に雇用保険事業所データによる補正を施したもの。
―――――
厚生労働省 政策統括官 (統計・情報政策担当) (2017) 『毎月勤労統計要覧』(平成28年版) 労務行政 ISBN:9784845272747 p. 297
この定義では、毎月勤労統計調査が月々推計している「前月末」の労働者数が「ベンチマーク」である。この値は毎月変動する。
以上のように、「ベンチマーク」についての厚生労働省の説明では、3種類の異なる定義が混在している。どれを採用するかによって、その指示対象がちがってくる。2021年5月の毎月勤労統計調査を例にとってみよう。最後にベンチマークを更新したのは2018年1月、そのときに使用したのは2014年の経済センサス-基礎調査の集計結果である。したがって、「ベンチマーク」が指示する対象はつぎのようになる。
- 第1の (当ワーキンググループによる) 定義では、2014年の経済センサス-基礎調査の集計結果を指す
- 第2の (2015年版までの『毎月勤労統計要覧』による) 定義では、2018年1月調査用に設定した前月末労働者数を指す
- 第3の (2016年版から2019年版の『毎月勤労統計要覧』による) 定義では、2021年5月調査用に推計した前月末労働者数を指す
こういう重要な用語について、複数の意味をあたえるのはやめてほしい。理解を妨げるうえに、議論をいたずらに複雑化して参加障壁を引き上げるだけなので。
もっとも、「ベンチマーク更新」という表現については、混乱は少ない。第1の定義と第2の定義のどちらでも、「ベンチマーク更新」は、センサスの情報を利用して毎月勤労統計調査で推計する母集団労働者数を変更する作業を指す。第3の定義ではベンチマークの数値は毎月新しくなるので、毎月更新しているといってもおかしくないはずだが、しかし実際には、「ベンチマーク更新」ということばは、通常の方法での月々の労働者数の推計には使わず、センサスの結果を参照して労働者数を設定した場合だけに限定して使っていたようだ。そうすると、どの定義を採用したとしても、「ベンチマーク更新」が意味する内容はおなじだということになる。
この記事ではこれ以降、混乱を避けるため、「ベンチマーク (の/を) 更新」という表現だけを使い、「ベンチマーク」単独では使用しないことにしよう。
データ
毎勤原表
以下で使うデータは、「政府統計の総合窓口 e-Stat」 https://www.e-stat.go.jp/stat-search/files?tstat=000001011791 に掲載の「毎月勤労統計調査全国調査結果原表」(「毎勤原表」と略称される) による。2021年8月14日に、つぎの2か所からExcelファイルをダウンロードした (下記ファイル名の ****** や **** には、年月をあらわす数字が入る)。
- 2004年1月から2011年12月まで
- 「実数原表・実数推計」の「時系列比較のための推計値(2004年1月~2012年1月)」から「月次」 (ファイル名: mks190_******.xls)
- 2012年1月から2021年5月まで
- 「実数原表・実数推計」の「実数原表(2012年1月~)」から「月次」 (ファイル名: hon-mks******.xls または sai****mks.xls)
これらのファイルは、東京都の事業所が他地域とはちがう抽出率で抽出されていた (それを適切なウエイトで復元していなかった) 問題などを事後的に訂正したものである。訂正の履歴についてはつぎの情報を参照:
- 厚生労働省「毎月勤労統計調査(全国調査・地方調査)」 https://www.mhlw.go.jp/toukei/list/30-1.html
- 厚生労働省「毎月勤労統計調査(全国調査・地方調査):過去のお知らせ」 https://www.mhlw.go.jp/toukei/list/30-1i.html
特に、2011年までの数値は、かなり強引な仮定を置いての推計結果であることに注意が必要である。これについてはつぎの情報を参照:
- e-Stat 「毎月勤労統計調査 全国調査」 https://www.e-stat.go.jp/stat-search/files?tstat=000001011791 から「実数原表・実数推計」→「時系列比較のための推計値(2004年1月~2012年1月)」→「作成方法の概要」→「「時系列比較のための推計値」作成方法の概要」(https://www.e-stat.go.jp/stat-search/file-download?statInfId=000031972600&fileKind=2 ファイル名:suikei-manual.pdf)
ちなみに、2003年以前の毎月勤労統計調査についての同様のデータは、「長期時系列表」の「実数・指数累積データ」から 「実数・指数累積データ 実数」(表番号1) のCSVファイル (hon-maikin-k-jissu.csv) にも (簡略なかたちで) 格納されている。しかし、このCSVファイルでは事業所規模500人以上はひとつのカテゴリーとなっており、1000人以上規模事業所を取り分けた分析ができない。今回は、ワーキンググループで提示された枠組みで分析を進めるため、1000人以上規模事業所についてのデータが抽出できる毎勤原表が公表されている2004年以降だけをひとまず対象とする。
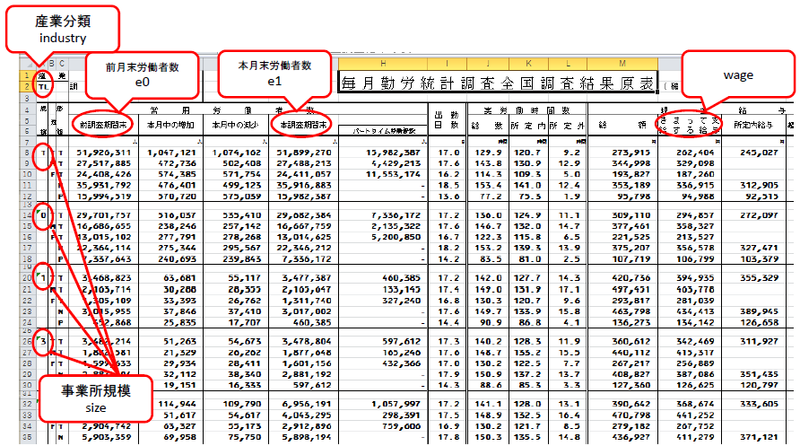
情報の抽出とテキスト・データ作成
毎勤原表のExcelファイルは、ひとつの産業について1枚の紙に印刷するようにできている。行の先頭フィールドがC-Rのアルファベットからはじまる文字列または「TL」(=全産業合計) である場合、産業分類をあらわす。先頭フィールドが「T」(=全事業所規模合計) あるいは1桁の数字である場合、事業所規模をあらわす。4番目と7番目のフィールドの数値がそれぞれ「全調査期間末」(=前月末) と「本調査期間末」(=本月末) の労働者数である (これらについては後述)。男女・就業形態別に1行ずつ数値が記載されているが、今回の分析で必要なのは男女・就業形態合計の数値だけなので、その1行だけ抽出すればよい。
https://www.e-stat.go.jp/stat-search/file-download?statInfId=000032108358&fileKind=4
―――――
「毎月勤労統計調査全国調査結果原表」(2021年5月分)
〔引用時に加工〕
データを抽出する Perl スクリプトを示す。毎勤原表のExcelファイルをすべてテキストファイルに変換して、このスクリプトを適用する。調査年月はファイル名からのパターンマッチで判断する。
# Option: # -all (without restriction of file name pattern) # -na (print lines with '-' or '*' to STDERR) %Option = ( all => 0 , na => 0) ; $Option{all}= 1 if grep { s/^\-all$//} @ARGV; $Option{na} = 1 if grep { s/^\-na$// } @ARGV; @ARGV = grep( $_ ne '', @ARGV ); $\ = "\n" ; $, = $" = "\t" ; %Class = ( # Size (workers in an establishment) 'T' => 0, # All sizes 1 =>1000, # 1000 and over 3 =>500 , # 500-999 5 =>100 , # 100-499 7 => 30 , # 30- 99 9 => 5 , # 5- 29 ) ; # Print the header (yyyymm for survey year-month; e0 and e1 for N of workers) print qw( file line yyyymm size e0 e1 wage industry ) ; FILE: foreach(@ARGV) { open (FILE, $_ ) || die("Cannot open file $_\n" ); my $Filename = $_; $Filename =~ s/\.txt$// ; my $Ym = '' ; if( $Filename =~ /hon\-mks(\d\d\d\d\d\d)/ ) { $Ym = $1 ; } elsif( $Filename =~ /mks190_(\d\d\d\d\d\d)/ ) { $Ym = $1 ; } elsif( $Filename =~ /(sai)?(\d\d)(\d\d)mks/ ) { my $ad = 1988 + $2 ; $Ym = $ad . $3 ; } # Filename pattern is restricted unless the option '-all' was specified next if '' eq $Ym && ! $Option{all} ; my $Line=0; my $Ind=''; while(<FILE>){ ++$Line; my @field = split /\t/; foreach(@field){ s/^[\"\s]*//; s/[\"\s]*$//; s/(\d),(\d)/$1$2/g ; } # Industry if( ( $field[0] eq 'TL' || $field[0] =~ /^[C-R]/ ) && $field[1] eq '' ) { $Ind = $field[0]; next; } # Establishment size my $class = $Class{ $field[0] }; next if $class eq '' ; next if( $Done{$Filename}{$Ind}{$class} ) ; # Number of workers my( $e0, $e1 ) = @field[3,6]; # Wage my($wage) = $field[13]; # Missing values my $na=0; ( $e0 =~ s/^[\-\*]$// ) && ++$na ; ( $e1 =~ s/^[\-\*]$// ) && ++$na ; ($wage=~ s/^[\-\*]$// ) && ++$na ; if( $Option{na} && $na ){ print STDERR $Filename, $Line , $Ym, $class, $e0 , $e1, $wage, $Ind, '||' . $_ ; } print $Filename, $Line , $Ym, $class, $e0 , $e1, $wage, $Ind; ++ $Done{$Filename}{$Ind}{$class}; } }
おなじ内容のスクリプト (の先頭に説明を付け加えたもの) を http://tsigeto.info/maikin/maikin-monthly.pl.txt に、出力結果 (タブ区切りテキストファイル 7MB) を http://tsigeto.info/maikin/maikin-monthly.dat.txt に置く。
毎勤原表の労働者数等のフィールドに、「-」「*」などが入っている場合がある。毎勤原表の説明 (mks.xls) にはこれらについての説明はない。しかし、e-Stat でデータベース化された毎月勤労統計調査の結果の出力 (たとえば https://www.e-stat.go.jp/dbview?sid=0003138108) では、「-」は数字が存在しないことを、「*」は秘匿措置によって数値が伏せられていることを示しているので、おそらくおなじ意味であろう。これらは、すべて欠損値としてあつかうことにする。
なお、毎月勤労統計調査で「労働者」というのは「常用労働者」のことである。ワーキンググループ資料等でも「労働者」といえば「常用労働者」のことであり、この記事でもそれにしたがっている。この「常用労働者」の定義が2018年1月に変更されており、これはこれで大きな問題なのであるが、この問題はこの記事では取り上げない (常用労働者定義問題については http://tsigeto.info/20a 第7節および https://remcat.hatenadiary.jp/entry/20190809/jss3 を参照)。
分析のためのRスクリプト
こうして抽出したデータを、Rで分析する。
x <- read.delim( "maikin-monthly.dat", header=T ) # Sort by date and establishment size x <- x[ order(x$size) , ] x <- x[ order(x$yyyymm) , ] x$is <- factor( paste( x$industry, x$size, sep="." ) ) x$year <- round( x$yyyymm / 100 ) x$month<- floor( x$yyyymm %% 100 ) x$worker2 <- ( x$e0 + x$e1 ) /2 x1 <- x x2 <- x x1$worker <- x1$e0 x2$worker <- x2$e1 x2$yyyymm <- x2$yyyymm + 0.5 temp <- rbind( x1, x2 ) x.long <- temp[ order(temp$yyyymm) , ]
各月のデータには、「前月末」(e0) 「本月末」(e1) の2種類の労働者数の値がある。これらを順に並べてあつかえるようにしたデータ・フレーム (x.long) をつくり、「本月末」労働者数に対応する月の数値に0.5を足しておく。 たとえば2021年5月分データの場合、「前月末」の労働者数については yyyymm==202105 であるが、「本月末」の労働者数については yyyymm==202105.5 のようにする。
データにはこまかい産業分類までふくまれているのだが、今回の分析では全産業合計のデータだけをあつかう。また、事業所規模別に分析できるよう、事業所規模別に整理したリストも用意する。
x.bysize <- subset( x.long, industry=="TL" & 0<size ) data <- list( size5 = x.bysize[ 5 == x.bysize$size , ], size30= x.bysize[ 30 == x.bysize$size , ], size100=x.bysize[100 == x.bysize$size , ], size500=x.bysize[500 == x.bysize$size , ], size1000=x.bysize[1000==x.bysize$size , ] )
月々の労働者数推計とベンチマーク更新の原理
毎月勤労統計調査では、母集団における労働者数を毎月推計し、その値を、平均賃金等を集計する際のウエイトとして使っている。この月々の母集団労働者数推計の手順はつぎの2段階にわかれていて、依拠する情報源が異なる。
- 調査対象事業所に雇用されている労働者数の変動 (毎月勤労統計調査による) の推計 (http://hdl.handle.net/10097/00127285 199ページ参照)
- 事業所新設・廃止等による変動 (雇用保険事業所データによる) と、事業所規模の変化などで別の層に事業所が移動したことによる変動 (毎月勤労統計調査による) の推計 (http://hdl.handle.net/10097/00127285 198-197ページ参照)
毎月勤労統計調査の毎回の調査では、前月 (前調査期間) の末日とその月 (本調査期間) の末日について、その事業所の労働者の人数をきいている。これで1ヶ月の間に労働者が何人増えたかがわかる。この労働者数増分に、賃金等を集計するときに使うのとおなじウエイトをかけると、母集団における労働者数の増分が推計できる。この分を、月はじめの推計母集団労働者数 (その月の「前月末」の労働者数と呼ばれる) に加えた値が、その月の「本月末」の推計母集団労働者数である (ちなみに毎勤原表においては、前月末労働者数は「前調査期間末」、本月末労働者数は「本調査期間末」と表記されている)。ここまでが第1段階。
https://www.mhlw.go.jp/toukei/chousahyo/30-1/dl/201905maikin1zenkoku.pdf
―――――
厚生労働省 (2019) 毎月勤労統計調査全国調査票(第一種事業所用)
〔赤枠は引用時に付加したもの〕
https://www.mhlw.go.jp/toukei/chousahyo/#00450071

母集団労働者数推計の第2段階は、つぎのふたつについて修正を加えるものである
- 事業所の新設/廃止、および事業所規模が5人以上になったり5人未満になったりしたケースの労働者数
- ある層から別の層に事業所が移動したことによる各層の労働者数の増減
前者については雇用保険事業所データ、後者については毎月勤労統計調査データを使用する。くわしくは https://www.soumu.go.jp/main_content/000615414.pdf の3ページおよび http://hdl.handle.net/10097/00127285 の198-197ページを参照されたい。
実例をあげて説明するために、近年の毎月勤労統計調査の5-29人規模の事業所の労働者数を抽出してみよう。
subset( data[["size5"]], 201901<=yyyymm, select=c( "yyyymm", "worker" ) )
グラフ1の折れ線は、毎月勤労統計調査の2019年4月から2021年5月までの5-29人規模の事業所の労働者数を示している。黒丸●は「前月末」の労働者数、白丸○は「本月末」の労働者数である。●→○ の変化は第1段階の推計による変化 (各事業所が毎月勤労統計調査に回答した、その月の労働者数の増減を母集団について推計したもの) であり、○→● の変化は第2段階の推計 (雇用保険等のデータに基づいて事業所新設/廃止/規模区分変更による労働者数増減を推計したもの) をあらわす。このように月々の母集団労働者数推計を繰り返していくことにより、毎月の「前月末」「本月末」の労働者数が変化していく。
ちなみに、これらのうち「前月末」の数値 (つまり黒丸) は、毎月勤労統計調査における賃金等の集計でウエイトとして利用しているものである。母集団労働者数推計の第1段階は、毎月勤労統計調査の通常の集計とおなじ方法で計算するものなので、このウエイトによる重み付けがおこなわれる。つまり、黒丸から白丸への値の変化量を計算するにあたっては、黒丸の数値自身がウエイトとして利用されている。
一方、第2段階 (白丸→黒丸) の推計にも、事業所規模区分が変更になった事業所の労働者数の推計に毎月勤労統計調査データを使うのだが、このときには、この前月末労働者数によるウエイトは使わない。かわりに、対象事業所をサンプリングしたときの抽出確率の逆数を使っている。*1
グラフ1: 5-29人規模事業所の2019年以降の労働者数推移と事業所母集団DBに基づくベンチマーク更新の影響
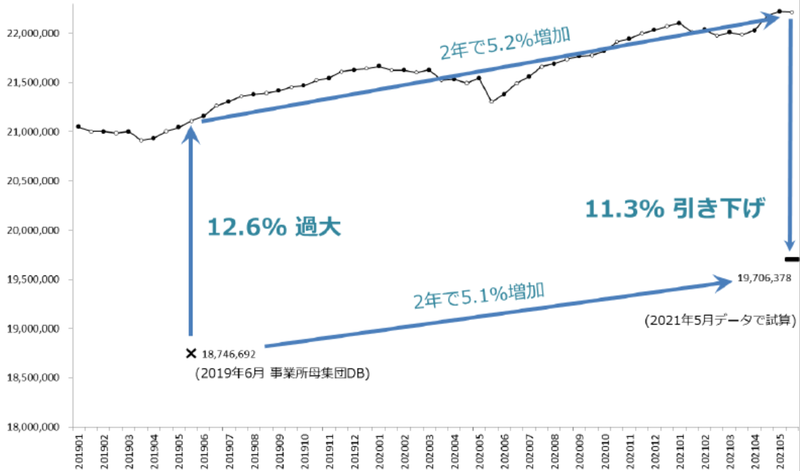
さて、今回のワーキンググループの資料1 によれば、事業所母集団データベースの「2019年次フレーム」(2019年6月) の5-29人規模事業所の労働者数は、対応する毎月勤労統計調査の推計母集団労働者数よりずいぶん低く、0.888倍だったという。ここでこの数値が毎月勤労統計調査のどの数値に対応しているかについて、資料の該当部分には「本月末労働者数」としか書いていないのだが、おなじ資料の15ページの記述から、2019年5月調査の本月末労働者数だと推測できる。これはおかしな話である。「2019年6月」の母集団労働者数の推計値 (すなわち母集団推定をおこなう際のウエイト算出に使うもの) といえるのは、2019年6月の「前月末」の労働者数だからだ。過去のベンチマーク更新の際にも、センサス調査月とおなじ月の「前月末」の労働者数との比をとって補正していた (下記参照)。今回に限ってこの前例を踏襲しない理由が説明されているわけでもない。が、「本月末」の数値を使うと会議資料にはっきり書いてあるのは確かなので、ここでも2019年5月の「本月末」労働者数との比をとることにしよう。幸い、2019年5月の「本月末」労働者数と、2019年6月の「前月末」労働者数の間には、それほど大きなちがいはない。
2019年5月の毎月勤労統計調査における5-29人規模事業所の「本月末」労働者数は、毎勤原表によれば2111万1140人である。事業所母集団データベースによる労働者数はこの0.888倍だというのだから、1874万6692人ということになる。毎月勤労統計調査が推計していた労働者数のほうが236万4448人多かったわけだ。
従来のベンチマーク更新の方法では、事業所規模と産業によって細分した層のそれぞれについてこのような計算をして「補正比」を求め、それを最新の毎月勤労統計調査の労働者数にかけることになる (http://hdl.handle.net/10097/00127285 196ページおよび https://remcat.hatenadiary.jp/entry/20190803/jss2#bench 参照)。ギャップが生じていたことがわかった時点までさかのぼって補正するわけではなく、最新のデータがえられたところで補正をおこなうので、その間にかなりの時間 (ふつう数年) が経過していることになる。
今回の会議で報告のあった試算は、2019年5月末時点のデータについてのずれから補正比を求め、それに基づいて2021年5月の本月末労働者数を補正したものである。2019年5月末の毎月勤労統計調査5-29人規模事業所の労働者数は、事業所母集団データベースの労働者数よりも12.6%過大であった。この分の補正を2021年5月末のデータに対して加えると、労働者数が11.3%減る (グラフ1)。
もし、2019年5月時点でのギャップが、偶発的で一時的な要因で数値が過大に出てしまっただけのものであったなら、このような修正でもまあよいわけである。たとえば、災害による混乱のために正確な調査をおこなうことが一時むずかしかったためにバイアスが生じた、というようなことであれば、他のデータと照合して判明したバイアス分を修正するというのは納得のいく方針である。混乱がおさまって平常の調査態勢にもどればそれ以降バイアスは出なくなるのだから、調査方法そのものを変更する必要はない。
これに対して、労働者数を過大あるいは過少に計測してしまうバイアスが調査や集計の方法自体に内在している場合、ベンチマーク更新によって数値のずれを修正するのは一時しのぎでしかない。ベンチマーク更新のあとも、そのバイアスはずっと作用しつづけるのである。
グラフ1では、毎月勤労統計調査の月々の推計母集団労働者数は、2019年5月から2021年5月までの2年間に5%増加している。ベンチマーク更新は2019年6月以降の変化には影響しないので、この増加が結果にそのまま反映する。だから、ベンチマーク更新後の2021年5月末の労働者数は、基準時点である2019年5月末から5%増えることになる。これが母集団における労働者数の増加を反映したものであれば――つまり真の労働者数も2年間に5%の率で増えてきたのなら――これで正しい。しかし、母集団では実際には増加していないのに調査方法あるいは集計方法の問題で増加しているとしたら、労働者数を過大に推計していることになる。調査/集計の方法がおかしいことが数値にずれを生む原因なのであれば、そこを治さなければ根本的な解決にならない。
2004年以後の毎月勤労統計調査とセンサスの乖離
センサスによる労働者数の推定
この問題を考えるには、2019年より前にさかのぼり、労働者数のずれがどうやって生じてきたのかを探る必要がある。
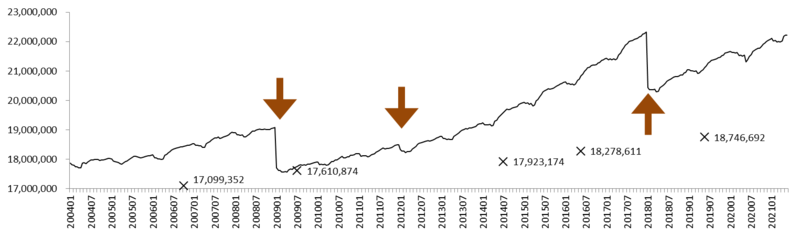
『毎月勤労統計要覧』によると、2004年以降にベンチマーク更新は3回あった:
- 2009年1月 (2006年10月事業所・企業統計調査による)
- 2012年1月 (2009年7月経済センサス-基礎調査による)
- 2018年1月 (2014年7月経済センサス-基礎調査による)
今回のワーキンググループ資料が提案する2016年経済センサス-活動調査と事業所母集団データベース2019年次フレーム (これらについては、ワーキンググループ資料の記述に基づき「本月末」労働者に対応させる) もふくめ、センサス時点に対応する毎月勤労統計調査データの年月はつぎのようになる。
census.date <- c( 200610, 200907, 201407, 201605.5, 201905.5 )
ベンチマーク更新が実際におこなわれた時点の前後をふくめ、問題となるタイミングの労働者数だけを集めた行列をつくっておく。
reset.date0 <- c( 200812.5, 201112.5, 201712.5 ) reset.date1 <- c( 200901 , 201201 , 201801 ) checkpoint <- c( census.date, reset.date0, reset.date1, 202105, 202105.5 ) x.cp <- subset( x.bysize, yyyymm %in% checkpoint ) size.cp <- sapply( split( x.cp , x.cp$yyyymm ), function(d){ d[ , "size" ] } ) worker.cp<-sapply( split( x.cp , x.cp$yyyymm ), function(d){ d[ , "worker" ] } ) rownames(worker.cp) <- size.cp[,1]
各センサスでの労働者数がいくつであったかの数値は、直接には知ることができない。毎月勤労統計調査による事業所規模にあわせて常用労働者数を示した統計データが公表されていないからである。しかし、その数値を使って2009年、2012年、2018年に毎月勤労統計調査の労働者数が変更されているので、そこから逆算することができる。
『毎月勤労統計要覧』(2010年版 290ページ) によれば、2009年のベンチマーク更新の手順は、産業・規模別に、2006年事業所・企業統計調査の常用雇用者数を2006年10月毎月勤労統計調査の前月末推計労働者数で割った値を2008年12月毎月勤労統計調査の本月末推計労働者数にかけ、その結果を2009年1月の前月末労働者数とした、というものである。2012年のベンチマーク更新においても、2009年経済センサス-基礎調査の結果をもとに、同様の手順がとられている (『毎月勤労統計要覧』2014年版 290ページ)。
したがって、2009年1月の前月末労働者数を2008年12月の本月末労働者数で割った値が、2006年事業所・企業統計調査での常用雇用者数と2006年10月の毎月勤労統計調査の前月末労働者数との比ということになる。2012年1月についても同様の計算ができる。
この操作は、本来であれば、産業別・事業所規模別にこまかく層にわけておこなうべきものだ。しかし今回は、事業所規模のみをわけ、産業合計について計算した。産業別にわけた場合、秘匿措置等のために労働者数が欠損値になっている層があって、その点の調整が面倒だったからである。センサスの時点とベンチマーク更新の時点との間で、事業所規模別にみた産業の構成比がおおきく変わっていなければ、産業合計の労働者数で計算しても結果は大差ないはずである。
gap2009 <- worker.cp[,"200901"]/ worker.cp[,"200812.5"] worker.pop2006 <- worker.cp[,"200610"] * gap2009 gap2012 <- worker.cp[,"201201"]/ worker.cp[,"201112.5"] worker.pop2009 <- worker.cp[,"200907"] * gap2012
2018年ベンチマーク更新については、手続きがちがう。2014年経済センサス-基礎調査 (7月) の常用雇用者数と2014年7月の前月末労働者数との比によって「補正比」を求めるところまではおなじだが、それを2017年12月の本月末労働者数にかけるのではない。ベンチマーク更新をおこなわずに2018年1月の前月末労働者数をいったん求め (=「旧サンプル」の母集団労働者数)、それに補正比をかけるのである。
5.平成30年1月分の新・旧集計等
事業所規模30人以上のサンプル入替え月(1月)には、旧サンプルと新サンプルの両者を調査対象としているところである。旧サンプルについては、先月までの集計と同様の集計を行う。新サンプルについても通常は旧サンプルと同様の処理を行うが、平成30年1月については、ベンチマーク更新を行ったため、母集団労働者数は経済センサスを元に作り直している。 〔……〕
6.集計に使用する母集団労働者数
https://www.soumu.go.jp/main_content/000636435.pdf
産業・事業所規模ごとに、平成26年経済センサスによる常用雇用者数を毎勤の平成26年7月分用母集団労働者数で割ったものを補正比とし、その補正比に旧サンプルの平成30年1月分用母集団労働者数を乗じたものを、新サンプルの平成30年1月分用母集団労働者数としている。
―――――
厚生労働省 政策統括官(統計・情報政策、政策評価担当)(2019-07-29) 「毎月勤労統計調査について」(第9回統計委員会点検検証部会 https://www.soumu.go.jp/main_sosiki/singi/toukei/tenkenkensho/kaigi/02shingi05_02000349.html 資料2) 10ページ
〔原文は表形式〕
この手続きにしたがって、2018年1月の「旧サンプル」の毎勤原表 (hon-mks-kyu201801.xls) を e-Stat からダウンロードし、そこから前述のPerlスクリプトによって抽出したデータ (maikin201801kyu.dat) を使うことにする。
kyu2018 <- read.delim( "maikin201801kyu.dat", header=T ) kyu2018 <- kyu2018[ order(kyu2018$size), ] kyu2018.tl0 <- subset( kyu2018, industry=="TL" & 0<size ) gap2018 <- worker.cp[,"201801"] / kyu2018.tl0$e0 worker.pop2014 <- worker.cp[,"201407"] * gap2018
2016年経済センサス-基礎調査と事業所母集団データベース2019年次フレームについても、ワーキンググループ資料1 の12ページでわかる毎月勤労統計調査とのギャップ率から計算しておこう。2016年については、5種類の試算がおこなわれているため、それらのギャップ率の幾何平均をとる。
# From https://www.mhlw.go.jp/content/10700000/000823050.pdf gap2019 <- c( 0.888, 1.092, 0.985, 0.813, 0.947 ) names( gap2019 ) <- c( "5", "30", "100", "500", "1000" ) worker.pop2019 <- worker.cp[,"201905.5"] * gap2019 census2016.rev <- rbind ( c( 0.878, 1.161, 0.960, 0.843, 0.971 ) , c( 0.880, 1.171, 0.960, 0.844, 0.973 ) , c( 0.877, 1.162, 0.959, 0.843, 0.977 ) , c( 0.877, 1.161, 0.960, 0.842, 0.970 ) , c( 0.877, 1.161, 0.960, 0.842, 0.970 ) ) gap2016 <- exp( apply( log(census2016.rev), 2, mean ) ) names( gap2016 ) <- c( "5", "30", "100", "500", "1000" ) worker.pop2016 <- worker.cp[,"201605.5"] * gap2016
これらをまとめると、ベンチマーク更新で利用してきたセンサス労働者数の行列がえられる。
worker.pop <- rbind( worker.pop2006, worker.pop2009, worker.pop2014, worker.pop2016, worker.pop2019 ) rownames(worker.pop) <- census.date
2004年1月から2021年5月までの毎月勤労統計調査における前月末・本月末労働者数と、上記の方法で推定したセンサス労働者数をまとめたデータ・フレームを下記のように求める。
temp <- sapply ( data[["size5"]]$yyyymm , function(i) { if( i %in% rownames(worker.pop) ) { r <- worker.pop[ as.character(i), ] } else { r <- rep( NA, ncol(worker.pop) ) } r } ) worker.pop.yyyymm <- t(temp) colnames(worker.pop.yyyymm) <- colnames(worker.pop) rownames(worker.pop.yyyymm) <- data[["size5"]]$yyyymm result <- lapply( data , function(d){ size <- d[1,"size"] r <- cbind( d$yyyymm, d$worker, worker.pop.yyyymm[ , as.character(size) ] ) colnames(r) <- c( "yyyymm", "worker", "census" ) rownames(r) <- rownames(d) data.frame(r) } )
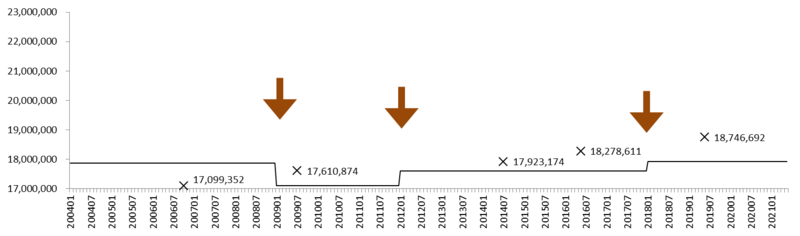
5-29人規模事業所
このデータ (result) を利用して、5-29人規模事業所について、前月末・本月末労働者数の変化をプロットしたのがグラフ2である。×は、センサスによる労働者数。矢印は、ベンチマーク更新をおこなった時点を示す。
グラフ2: 労働者数の推移 (5-29人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
このグラフから、毎月勤労統計調査が月々推計する労働者数は、微細な振動をともないながら、増加を続けてきたことがわかる。センサスによる労働者数も増加はしているのだが、毎月勤労統計調査の労働者数のほうが、それを上回る速度で増加してきた。この傾向は、2013年あたりから加速している。2009年のベンチマーク更新では、労働者数をセンサスと同等の水準にいったん引き下げているが、その後すぐに増加し、2014年、2016年にはセンサスの労働者数をはるかに上回っている。2018年のベンチマーク更新では、労働者数を引き下げはしたものの、センサスの水準とは乖離したままの状態にある。
では、もし月々の労働者数推計をおこなわなかったとしたら、どうなっていただろうか。2009年1月、2012年1月、2018年1月にベンチマークの更新をおこなう (つまりセンサスの労働者数をコピーする) が、それ以外の月には前月の労働者数をコピーするという設定でデータ・フレームをつくりなおしてみる。
noinc <- lapply( data, function(d) { size <- d[1,"size"] d$census <- worker.pop.yyyymm[ , as.character(size) ] d$noinc <- NA d[1, "noinc"] <- d[1, "worker"] d[ d$yyyymm==200901, "noinc" ] <- worker.pop[ "200610" , as.character(size) ] d[ d$yyyymm==201201, "noinc" ] <- worker.pop[ "200907" , as.character(size) ] d[ d$yyyymm==201801, "noinc" ] <- worker.pop[ "201407" , as.character(size) ] for( i in 2:nrow(d) ) { if( is.na( d[ i, "noinc"] ) ) { d[ i, "noinc"] <- d[ i-1, "noinc"] } } d } ) result2 <- lapply( noinc , function(d){ d$worker <- d$noinc d[ , c( "yyyymm", "worker", "census" ) ] } )
この result2 による5-29人規模事業所の労働者数推移がグラフ3である。
グラフ3: 月々の労働者数推計がなかった場合の労働者数の推移 (5-29人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
グラフ3では、労働者数のラインはほとんど平坦で、センサスの値にすこし遅れて追随するだけである。グラフ2と比較すると、2009年7月経済センサス-基礎調査以外では、グラフ3のほうがセンサスの値に近い。グラフ2で2016年や2019年の値が大きく乖離していたのに比べ、ずっと差が小さくなっている。
この結果から見る限り、5-29人規模事業所でみられた労働者数のセンサスからの乖離は、ほとんど月々の労働者数推計の結果として生じている。センサスの値が正しいものと考えるかぎり、毎月勤労統計調査の月々の労働者数推計は、やらないほうがまし だったのである。
30-99人規模事業所
上記の result, result2 は5-29人規模事業所以外についての結果もふくんでいる。
30-99人規模事業所について、労働者数の推移を描いたのがグラフ4である。
グラフ4: 労働者数の推移 (30-99人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
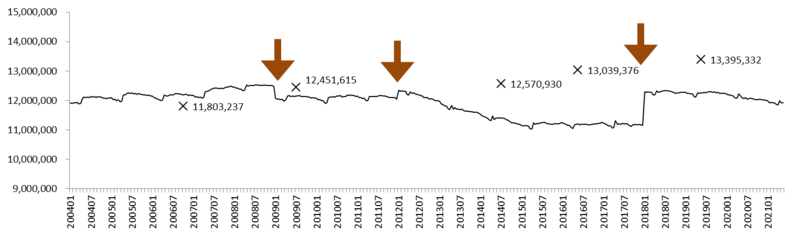
2009年までは、センサスの値をよく追尾している。ところが2012年から労働者数が下がりはじめ、2015年まで下がりつづける。このため、2014年と2016年は、センサスよりも下方に大きくずれている。2018年のベンチマーク更新で上昇したものの、センサスの水準には達しなかった。それ以降、労働者数は減少気味であり、センサスと乖離がひろがる傾向にある。
この間、センサスによる労働者数は単調に増加している。それにもかかわらず毎月勤労統計調査の推計労働者数が大きく減少してきたのは不審である。推計の方法または実際の計算手続きになにか瑕疵があったのではないだろうか。
グラフ5: 月々の労働者数推計がなかった場合の労働者数の推移 (30-99人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
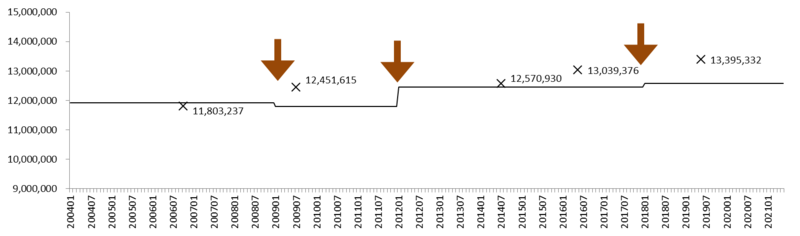
月々の労働者数推計をおこなっていなければ、30-99人規模事業所の2012年以降の労働者数は、センサスに近い値になっていたと予測できる (グラフ5)。2009年の値をのぞけば、労働者数推計を毎月おこなう現行の毎月勤労統計調査の数値 (グラフ4) のほうが、センサスからの乖離が大きい。
100-499人規模事業所
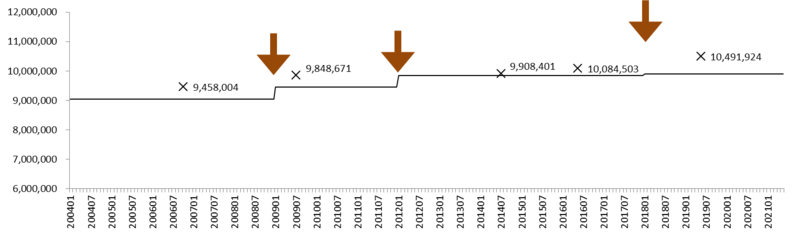
グラフ6: 労働者数の推移 (100-499人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
100-499人規模事業所について、労働者数の推移を描いたのがグラフ6である。この規模では、毎月勤労統計調査が推計する労働者数とセンサスの間には、食い違いはあまりない。
グラフ7: 月々の労働者数推計がなかった場合の労働者数の推移 (100-499人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
月々の労働者数推計をおこなわなかった場合 (グラフ7) も、センサスとの乖離はそれほど大きくはならない。ただ、いちばん新しい2019年に関しては、かなり過少となっている。現在以降の統計の精度という観点から考えるなら、労働者数推計をおこなうことのメリットはあるのかもしれない。
500-999人規模事業所
グラフ8: 労働者数の推移 (500-999人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
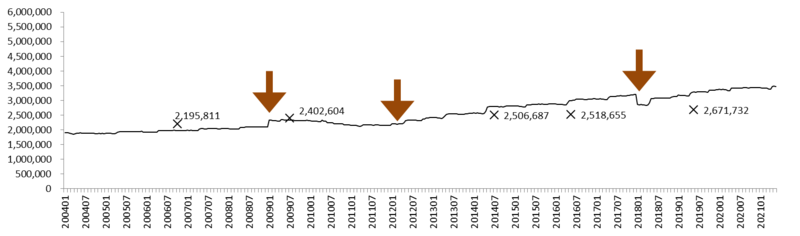
500-999人規模事業所について、労働者数の推移を描いたのがグラフ8である。この規模の事業所の労働者数は、2014年以降、センサスの値を上回って増加をつづけている。とはいえ、5-29人規模事業所ほどには超過の幅は大きくない。
グラフ9: 月々の労働者数推計がなかった場合の労働者数の推移 (500-999人規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
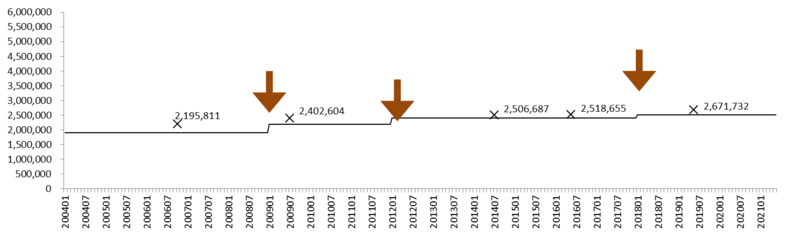
月々の労働者数推計をおこなわない設定でグラフを描くと、センサスとの乖離はかなり小さくなる (グラフ9)。この規模の事業所に関しても、やはり毎月勤労統計調査の労働者数推計方式は問題ありそうである。
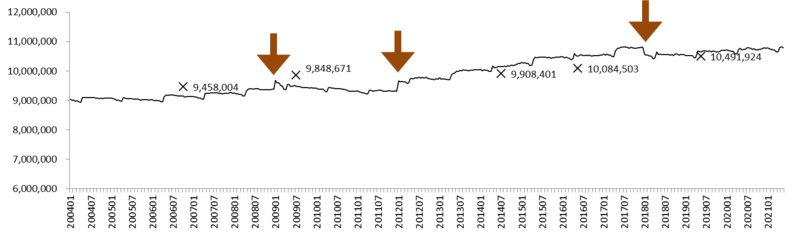
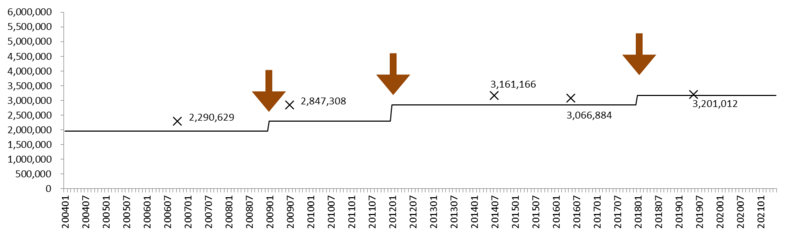
1000人以上規模事業所
グラフ10: 労働者数の推移 (1000人以上規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
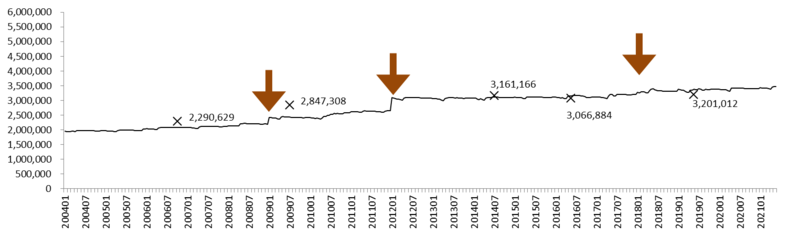
1000人以上規模事業所について、労働者数の推移を描いたのがグラフ10である。2012年のベンチマーク更新までは労働者数の推計はやや過少であったものの、それ以降は非常にセンサスの数値に近い値となっている。
グラフ11: 月々の労働者数推計がなかった場合の労働者数の推移 (1000人以上規模事業所)
×: センサスによる労働者数。 矢印: ベンチマーク更新。
グラフ11は、月々の労働者数推計がなかった場合の予測値である。グラフ10にくらべると、2014年、2016年の経済センサスとの乖離がすこし大きい。ただ、ずれている人数自体は大きくはなく、センサスの数値をよく近似できている。
月々の労働者数推計の有無による差の評価
月々の労働者数推計をするかしないかによってセンサスとの乖離がどう変化するかについて、種々の観点から評価するための指標群をつくってみた。
worker.census.gap <- function(d){ c <- subset( d, !is.na(census) ) c$gap <- c$worker / c$census c } result.gap <- lapply( result, worker.census.gap ) result2.gap<-lapply( result2, worker.census.gap ) gap.table <- data.frame() for( s in names(result.gap) ) { r <- result.gap[[s]] r$is <- s r$noinc <- result2.gap[[s]]$worker r$gap2 <- result2.gap[[s]]$gap r$gap.rate <- r$gap / r$gap2 r$diff1 <- r$worker - r$census r$diff2 <- r$noinc - r$census r$diff.diff <- abs( r$diff1 ) - abs( r$diff2 ) gap.table <- rbind( gap.table, r ) } temp <- split( gap.table, gap.table$is ) diff.diff <- sapply( temp, function(d){ d[, "diff.diff"] } ) rownames(diff.diff) <- result.gap[["size5"]]$yyyymm diff.diff <- diff.diff[ , names(result.gap) ] round( addmargins(diff.diff) )
最後の diff.diff は、労働者数推計のある場合とない場合のそれぞれについて、センサスとの差の絶対値を計算し、それらの間の差を求めたものである (ある場合-ない場合)。プラスであれば労働者数推計をおこなった場合のほうがセンサスとの乖離が大きいことを、マイナスであれば推計なしのほうが乖離が大きいことを示す。
size5 size30 size100 size500 size1000 Sum 200610 564060 269806 -120448 -76326 -110955 526137 200907 -349875 -351200 -31801 -138973 -144307 -1016156 201407 1356036 1052634 185065 186584 -262137 2518181 201605.5 1876877 1241634 186546 353732 -131867 3526921 201905.5 1540929 304142 -423747 449486 139302 2010112 Sum 4988028 2517015 -204385 774503 -509965 7565196
この値は、2009年経済センサス-基礎調査のみ、すべての事業所規模でマイナスである。この時点では、労働者数推計によってセンサスの値に近づける効果のあったことがわかる。2006年10月から2009年7月の間、センサスによる労働者数は、どの事業所規模区分でも増加していた。この時期の毎月勤労統計調査は、この母集団労働者数の増加を適切に推計していたといえる。もっとも、2009年1月にベンチマーク更新をおこなった半年後であったこともあり、乖離の縮小幅は最大でも35万人程度で、それほど大きくない。
それ以外の年に関しては、5-29人規模と30-99人規模の事業所で、大きなプラスの値が出ている。特に2014年と2016年には100万人を超える。これらの比較的小規模な事業所では、労働者数推計をおこなうことでかえって乖離が大きくなっているのである。
1000人以上規模事業所では、2019年以外は値がすべてマイナスになっており、労働者数推計が有効にはたらいている。最新の2019年のみプラスであるが、14万人程度なので、大きく外れているわけではない。
100-500人規模と500-999人規模の事業所も、それほど状況は悪くない。ただし、500-999人規模では徐々に数値が大きくなってきているのが気になるところではある。
議論
毎月勤労統計調査の月々の労働者数推計は、センサスの数値から外れている。ワーキンググループで検討の対象となった2016年経済センサス-活動調査と事業所母集団データベース2019年次フレームのどちらも、毎月勤労統計調査の推計母集団労働者数との間に大きなギャップがある。どちらの値を採用するにせよ、次回のベンチマーク更新時には、労働者数に突然の変動が生じることになる。
また、この労働者数のずれは、ベンチマーク更新の基準となるセンサスのデータ収集時点 (2016年6月または2019年6月) からベンチマーク更新 (2022年1月?) までの間に拡大しているだろう。この点も問題である。このベンチマーク更新時点の値を起点として過去に向かって「指数」を修正する、現在提案されているギャップ修正のやりかた (ワーキンググループ資料1 の15ページ) では、修正後の値もこのバイアスをふくんでしまうことになる。
上記の分析で示したように、センサスの値が真の母集団労働者数だと考えるのであれば、まずは毎月勤労統計調査の月々の労働者数推計を停止すべきである。次回センサスの数値が判明するまでずっとおなじ労働者数を使いつづける――つぎのセンサスの結果が手に入ったところで、それにあわせて修正する――という単純な手法をとったほうが、数値のずれはすくない。過去の指数を書き換えるのであれば、各センサスの労働者数をその時点の労働者数として採用し、その間を何らかの仮定 (たとえば毎月一定の率で変化する、など) をおいた推測値で補完するのがよいだろう。最後のセンサスから現在までの労働者数についても、過去のトレンドを現在まで延長した数値を暫定的に使用する――将来、センサスの値が入手できたところで、さかのぼって指数を修正して確定させる――というやりかたがある。
もし、月々の労働者数推計を維持することに妥当性があるとしたら、それは、センサスの数値よりも毎月勤労統計調査の推計のほうが真の値に近い場合だ。しかしその場合、センサスの数値のほうが間違っているということなのだから、センサスを基にベンチマーク更新をおこなう理由自体がないことになる。実際、経済センサス等で把握できる事業所が偏っているという指摘はある (たとえば西村淸彦+山澤成康+肥後雅博 (2020)『統計 危機と改革: システム劣化からの復活』日本経済新聞出版 ([ISBN:9784532135089] 125-131ページ) や朝日新聞の2020年11月28日の記事 https://www.asahi.com/articles/DA3S14711643.html を参照)。センサスがおかしくて毎月勤労統計調査のほうが正しいということはありうる。
このような判断をくだすには、もっとくわしい情報が必要となる。上記の分析でも、センサスとの乖離の方向と度合いは、事業所規模と時期によってちがっていることがわかる。5-29人規模事業所では、2004年以降ずっと、センサス結果を上回る増加がつづき、このために大きなギャップが継続して生じている。一方で、30-99人規模事業所では、推計される労働者数が減少したために、増加気味であったセンサス結果との間に乖離があるが、この傾向は2012-2015年の間に集中している。100-499人規模事業所や1000人以上規模の事業所では、毎月勤労統計調査の月々の労働者数推計はセンサスの数値とほとんどずれておらず、ずっと高い精度で追尾できている。このようなちがいが出てくる原因を突き止められれば、毎月勤労統計調査とセンサスのどこにまずい点があり、どのように修正するべきであるかについて、有用な知見がえられるだろう。
使用したプログラムとデータ
- 毎勤原表から情報を抽出するPerlプログラム
- http://tsigeto.info/maikin/maikin-monthly.pl.txt
- 分析用Rプログラム
- http://tsigeto.info/maikin/maikin-monthly.r.txt
- 毎勤原表2004年1月-2021年5月のデータ
- http://tsigeto.info/maikin/maikin-monthly.dat.txt
- 毎勤原表2018年1月「旧サンプル」のデータ
- http://tsigeto.info/maikin/maikin201801kyu.dat.txt
- その他の情報
- http://tsigeto.info/maikin/
これらのプログラムとデータを使用するときは、ファイル名末尾の「.txt」を削るか、プログラム中のファイル名指定部分に「.txt」を加える。
つづき:
母集団労働者数推計の謎:毎月勤労統計調査とセンサスはなぜ乖離しているのか
https://remcat.hatenadiary.jp/entry/20210920/workerpop (9月20日)
履歴
- 2021-09-11
- 公開
- 2021-09-22
- 「「ベンチマーク」の3つの意味」に『毎月勤労統計要覧』2020年版 (令和2年版) についての記述を追記。
- 2021-12-28
- 「つづき」を追記
注
*1:この記述は、統計委員会からの要望に対する厚生労働省の回答 (2019年4月18日 https://www.soumu.go.jp/main_content/000615414.pdf) の3ページによる。ただし、毎月勤労統計調査の改善に関するワーキンググループの第1回会議の資料1 https://www.mhlw.go.jp/content/10700000/000802074.pdf の7ページや16ページにはまたちがう説明が書いてあるので、真相はよくわからないところである。